Encodings 101 — A Comprehensive Guide to Supervised and Unsupervised Encoding Strategies

Categorical variables are an essential component of many datasets, but they cannot be directly used in most machine learning models. To leverage their valuable information, we need to encode them into numeric representations. In this article, we will explore different encoding strategies that can be applied to categorical variables, both in unsupervised and supervised scenarios.
Create the Dataset
Let's import the necessary libraries and create a sample dataset used for demonstration purposes for this article!
import numpy as npimport pandas as pd
# Import Encoders
from category_encoders import OrdinalEncoder, OneHotEncoder, CountEncoder, BinaryEncoder, HashingEncoder, JamesSteinEncoder, MEstimateEncoder, CatBoostEncodercategories = ['Ronaldo', 'Messi', 'Neymar']
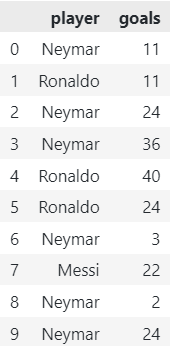
df = pd.DataFrame({
'player': np.random.choice(categories, 10),
'goals': np.random.randint(low=1, high=50, size=10)
})
Unsupervised Encoding Strategies
Unsupervised encoding strategies do not rely on the target variable to encode categorical variables. Let’s delve into some popular techniques:
1. Label Encoder
The Label Encoder assigns a unique numeric label to each unique category present in the variable. It is a straightforward approach that maps each category to an integer value. However, it does not consider any underlying order or relationship between categories. Thus, it may not be suitable for certain models.
df_encoded = OrdinalEncoder(cols=['player']).fit_transform(df)
# Get original player names
df_encoded['player_original'] = df['player']
# Reorder Elements
df_encoded = df_encoded[['player_original', *df_encoded.columns[:-1]]]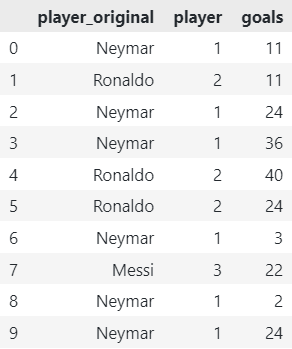
2. One-Hot Encoder
The One-Hot Encoder transforms each category into a binary vector, where only one element is active (1) and the rest are inactive (0). This representation allows models to understand that categories are mutually exclusive. However, it can lead to a significant increase in feature dimensionality when dealing with a large number of categories.
# Encode Player Column
# Use Cat Names Parameter adds the category name to the column
df_encoded = OneHotEncoder(cols=['player'], use_cat_names=True).fit_transform(df)
# Get original player names
df_encoded['player_original'] = df['player']
# Reorder Elements
df_encoded = df_encoded[['player_original', *df_encoded.columns[:-1]]]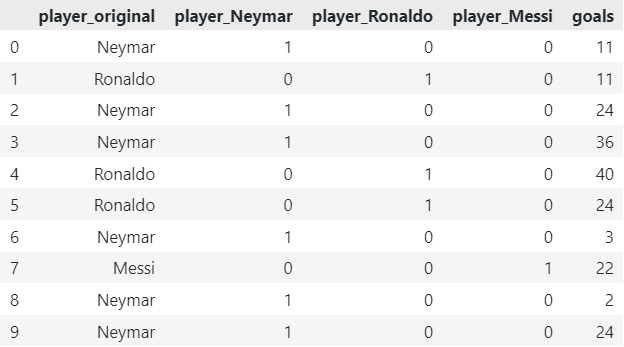
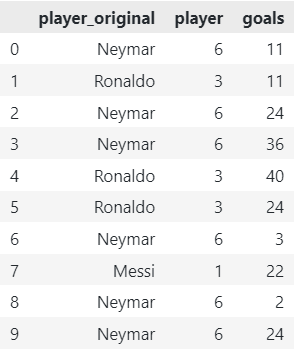
3. Frequency Encoder
The Frequency Encoder replaces each category with its corresponding frequency or count in the dataset. This encoding strategy captures valuable information about the distribution of categories. However, it may not be robust against rare categories with low frequencies.
4. Binary Encoder
The Binary Encoder represents each category with a binary code. It reduces dimensionality compared to One-Hot Encoding while preserving information about category relationships. Binary encoding is achieved by assigning a unique binary code to each category and using multiple columns to represent the code.
df_encoded = BinaryEncoder(cols=['player']).fit_transform(df)
# Get original player names
df_encoded['player_original'] = df['player']
# Reorder Elements
df_encoded = df_encoded[['player_original', *df_encoded.columns[:-1]]]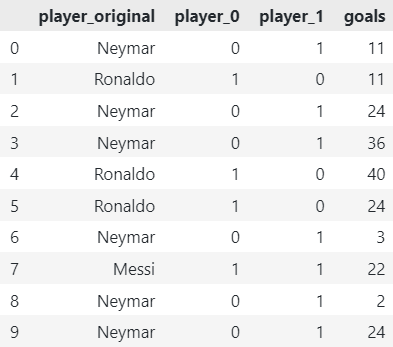
5. Hashing Encoder
The Hashing Encoder applies a hash function to each category and assigns a fixed number of columns to represent the hashed values. This technique reduces dimensionality and is particularly useful when memory efficiency is a concern. However, it may introduce collisions, where different categories are mapped to the same hash.
df_encoded = HashingEncoder(cols=['player']).fit_transform(df)
# Get original player names
df_encoded['player_original'] = df['player']
# Reorder Elements
df_encoded = df_encoded[['player_original', *df_encoded.columns[:-1]]]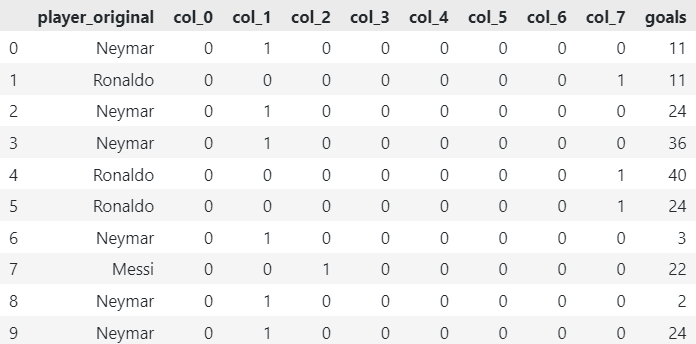
Supervised Encoding Strategies
Supervised encoding strategies incorporate information from the target variable to encode categorical variables. Let’s explore some powerful techniques:
1. Target Encoder
The Target Encoder, also known as Mean Encoder, replaces each category with the mean of the target variable for that category. It leverages the relationship between the category and the target, providing valuable information to the model. However, it may overfit when dealing with rare categories or datasets with a small number of observations.
# Reset DataFrame
df_encoded = pd.DataFrame(None)
df_encoded.loc[:, "player"] = pd.DataFrame(df.groupby("player")["goals"].transform("mean"))
df_encoded['goals'] = df['goals']
df_encoded['player_original'] = df['player']
# Reorder Elements
df_encoded = df_encoded[['player_original', *df_encoded.columns[:-1]]]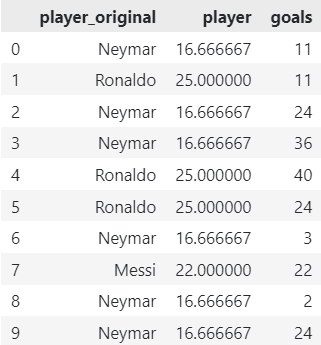
2. James-Stein Encoder
The James-Stein Encoder is a regularization technique that shrinks the target means towards the overall mean. It prevents extreme estimates and improves generalization. This encoder performs well when the target variable exhibits heterogeneity across categories.

df_encoded = JamesSteinEncoder().fit_transform(X=df, y=df['goals'])
# Get original player names
df_encoded['player_original'] = df['player']
# Reorder Elements
df_encoded = df_encoded[['player_original', *df_encoded.columns[:-1]]]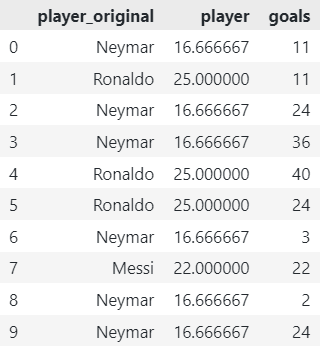
3. M-Estimate Encoder
The M-Estimate Encoder is a smoothed version of the Target Encoder that incorporates a regularization parameter. It prevents overfitting and handles rare categories more effectively. It can be tuned to control the amount of smoothing applied.
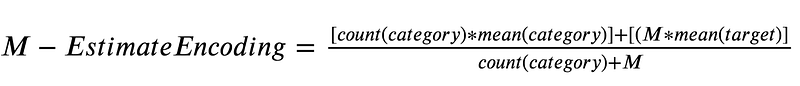
df_encoded = MEstimateEncoder().fit_transform(X=df, y=df['goals'])
# Get original player names
df_encoded['player_original'] = df['player']
# Reorder Elements
df_encoded = df_encoded[['player_original', *df_encoded.columns[:-1]]]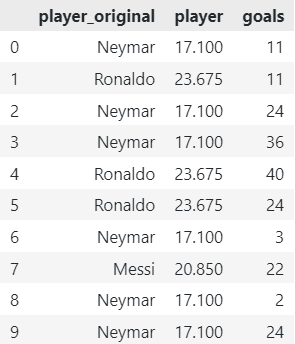
4. Catboost Encoder
The Catboost Encoder, inspired by the CatBoost gradient boosting algorithm, is similar to the Target Encoder but also considers the target variable’s ordering. It captures complex relationships and performs well in cases where the target variable exhibits non-linear behavior.
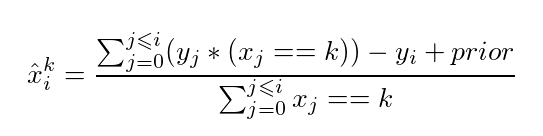
df_encoded = CatBoostEncoder().fit_transform(X=df, y=df['goals'])
# Get original player names
df_encoded['player_original'] = df['player']
# Reorder Elements
df_encoded = df_encoded[['player_original', *df_encoded.columns[:-1]]]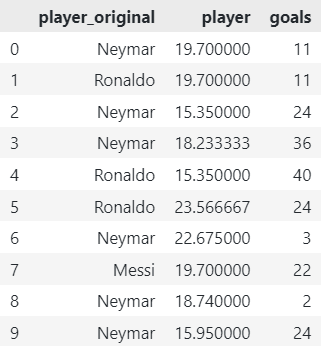
Libraries Used
During this notebook, we employed several libraries to implement the encoding strategies:
- Category Encoders: A comprehensive library for encoding categorical variables, providing implementations of various encoding techniques.
- NumPy: A powerful library for numerical computing in Python, which provides efficient data structures and mathematical functions.
- Pandas: A versatile library for data manipulation and analysis, offering convenient data structures and operations for handling datasets.
Conclusion
In this article, we explored different strategies to encode categorical variables into numeric representations. We covered unsupervised encoding techniques like Label Encoder, One-Hot Encoder, Frequency Encoder, Binary Encoder, and Hashing Encoder. These methods are useful when we want to transform categorical variables without relying on the target variable.
We also discussed supervised encoding strategies such as Target Encoder, James-Stein Encoder, M-Estimate Encoder, and Catboost Encoder. These methods incorporate information from the target variable, allowing models to better capture relationships and patterns between categories and the target.
By understanding and applying these encoding strategies, you can effectively preprocess categorical variables and enhance the performance of your machine learning models.
Remember, the choice of encoding strategy depends on various factors such as the nature of the data, the number of categories, and the behavior of the target variable. It is crucial to experiment with different encoders and evaluate their impact on your specific dataset.
You can find the code implementation and further details in the Jupyter Notebook accompanying this article.
For a more detailed demonstration and implementation of these encoding strategies, I highly recommend checking out my YouTube video on the topic. Watch it HERE to gain a deeper understanding and practical insights.
I hope this article has provided you with a comprehensive understanding of different encoding strategies for categorical variables. Happy encoding and machine learning!
